Database Architecture
Normalization
To normalize a database, we restructured it in accordance to a series of normal forms that avoids the redundancy of data, undesirable dependencies, and inconsistencies.
In his paper “Further Normalization of the Data Base Relational Model" [4], Edgar F. Codd, the “father” of the relational database model, listed these objectives of normalization:
- To free the collection of relations from undesirable insertion, update and deletion dependencies.
- To reduce the need for restructuring the collection of relations, as new types of data are introduced, and thus increase the life span of application programs.
- To make the relational model more informative to users.
- To make the collection of relations neutral to the query statistics, where these statistics are liable to change as time goes by.
The following set of tables serves as an example for a database that is not properly normalized.
Table one:
| username | word | word_language | translation | translation_language |
|---|---|---|---|---|
| Mark | house | en | Haus | de |
| Dana | house | en | maison | fr |
| Eamon | casa | es | house | en |
Table two:
| id | username | is_admin | |
|---|---|---|---|
| 1001 | Dana | dana@email.com | true |
| 1002 | Eamon | eamon@email.com | true |
| 1003 | Mark | marc@email.com | false |
Table one holds the values of four key entities: users, words, translations, and languages. Table two maintains user information.
Two independent username columns exist in two tables: an example of redundancy that can lead to so-called “update anomalies”. If we discover after the initial insertion that user with username Marc is not spelled with a “k” but with a “c”, and only proceed to change this data in the users table, then data across the database will become inconsistent. The username needs to be updated in two different places, making database updates open to errors.
Normal forms
Normalization of relational databases is guided by rules that build on each other called “normal forms”.
To satisfy the the first normal form (1NF), data sets must not contain tables themselves, and each data set must have a unique primary key. In the example above, with no nested tables and primary key for only the users table, 1NF is not satisfied.
The second normal form (2NF) must fulfil rules of the first normal form, and demands every attribute of a data set to be functionally dependent on the primary key. Attributes not dependent on the primary key belongs to their own table.
The third normal form (3NF) requires 2NF and requires the elimination of any transitive functional dependencies. For example, if B depends on primary key A, but C depends on B, then both B and C should be extracted to their own table.
Within the scope of Alexandria, our database was designed to satisfy 3NF, thus protecting it from insertion, update and deletion anomalies.
Tables
We started out with a few iterations of basic design. This is one of the first drafts:
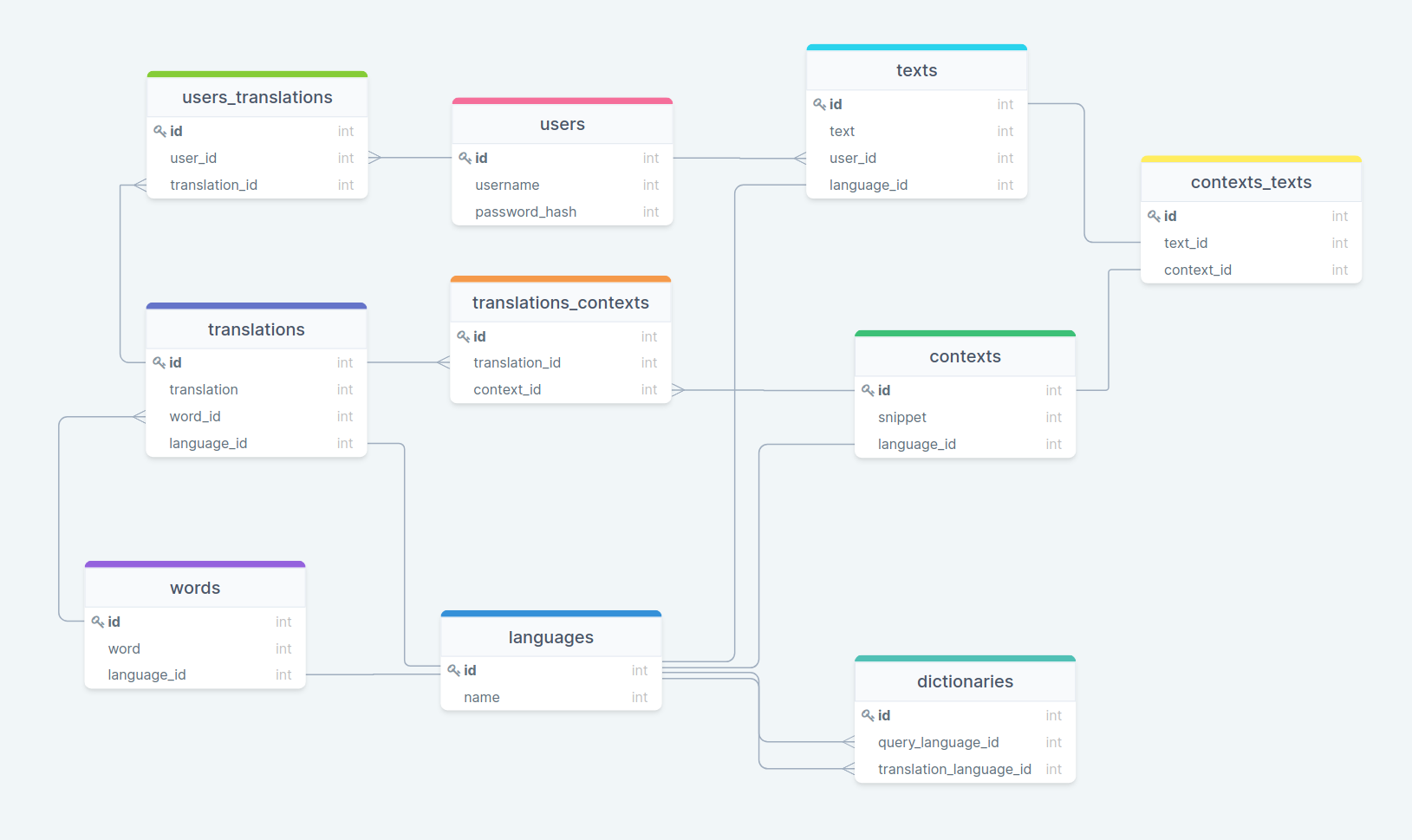
As our understanding and ambitions of Alexandria’s user needs and functionalities grew, the number of tables in our database grew. Here’s a few examples of additional features we considered implementing for the MVP:
- User having access and choosing from other users' translations
- Saving every existing translation with a new context
- Users setting favourite dictionaries
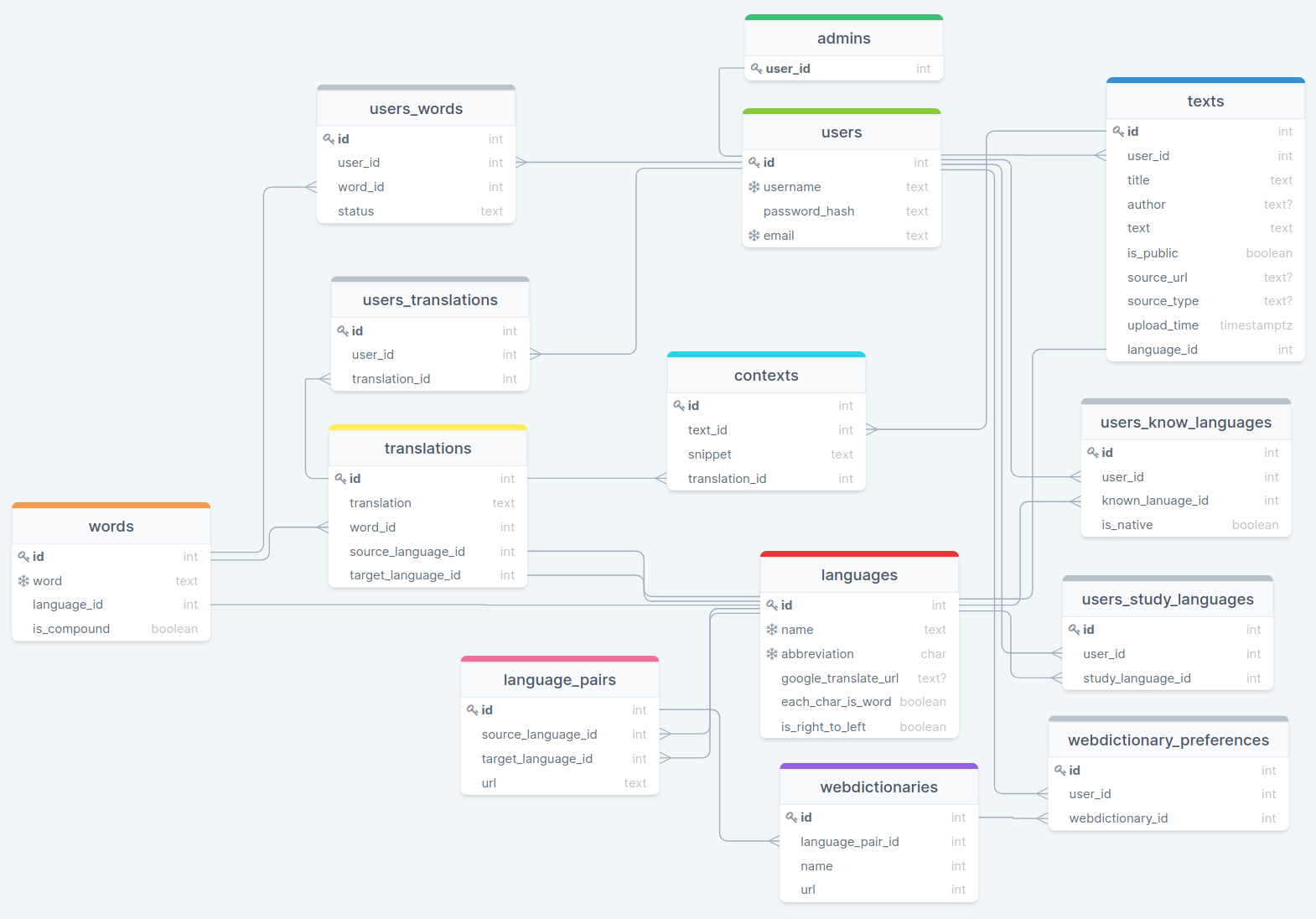
Once we pared down Alexandria’s feature list to arrive at a MVP, our database complexities shrank. The reduced scope supports a single-user experience, simplified user profile and context handling, while laying the groundwork for cross-user content sharing.
This is what we arrived at for the initial release of Alexandria:
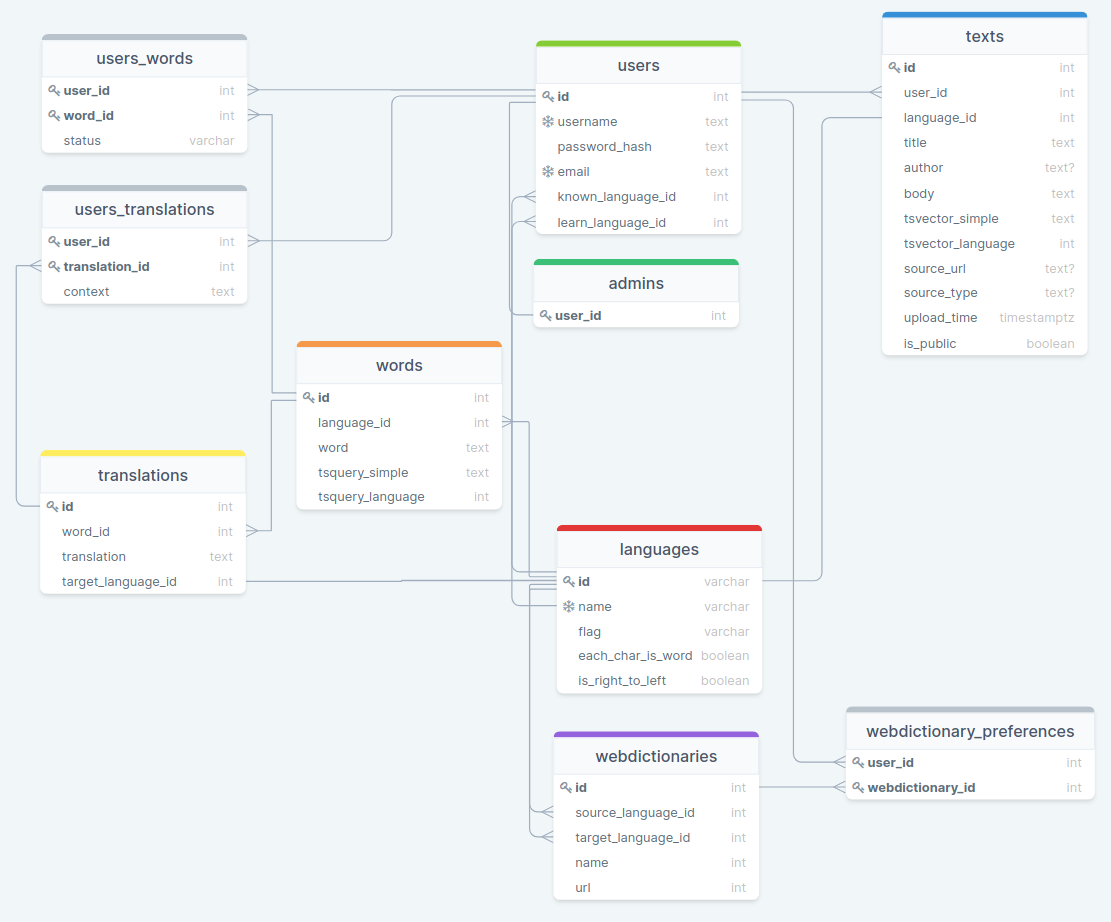
In the final design, we stripped the connecting tables of their own unique ids, and made composite keys - the combinations of foreign key columns - the primary keys. This ensures that connections are unique and a user cannot have two statuses for the same word.
We left in id as the primary key for the words table while acknowledging it could have been possible to replace unique keys with composite keys - as every word is unique in its own language. Bar one table, Alexandria has achieved 3NF.
Naming things
As a useful side effect of designing the database early on, we were forced to come to a common understanding of naming entities in our code. For example, what is a word, and what is a phrase? Finding that common language was essential for communication going forward.
Alexandria’s MVP database tables
Main tables
| table | description |
|---|---|
| users | The people using Alexandria. Each user can actively learn one language at a time, and translate to one base language. If language preferences change, previous progress (translations, word statuses) is kept. |
| admins | The people administering Alexandria. That would be the core development team for now. |
| languages | The languages that are supported by Alexandria. For the first release, it is a list of ten. What they have in common is their use of a Latin-based alphabet (to avoid surprises with our text parser), in addition to language support by PostgreSQL text search. A flag representing the language is saved as a unicode character combination to be used in menus across the application. |
| texts | The key entity for learning. Texts are currently provided by users through forms, later through URLs and files. Texts default to private, which should particularly suit those who learn best by reading state secrets or erotic literature. Public texts accessible to every user is on the roadmap for a future release. Database is created with necessary column to provide this functionality. |
| words | Translatable entities. Usually single words like cabbage, but also compounds, or phrases, like get up or l’hôtel. Each word must be unique within its language. It can have different meanings (translations) but in database terms, each combination of letters occurs once per language. |
| translations | Translations of words can be provided or selected by the users, but they exist independently of the users who created them. Since a word is aware of the language it’s in, the translation table tracks only the language a word is translated to, in column target_language. Seeding the database with a language’s most common words and translations could be another future release feature. |
| webdictionaries | Online resources where user can look up a word or phrase. |
Connecting tables
| table | purpose |
|---|---|
| users_words | Word statuses for a user-word combination are “learning”, familiar”, and “learned”. User dictionaries could be generated using this table. |
| users_translations | Every translated word originates in a text. Surrounding words from that text form the translation’s context. Users have their own contexts for every translation. If the translation is not newly provided but simply selected from previous translations, current context is saved and connected to the current translation and user. |
| webdictionary_preference | Users can have one favourite dictionary per source language. |